| CPC H04L 12/1818 (2013.01) [G06F 40/58 (2020.01); G10L 15/005 (2013.01)] | 15 Claims |
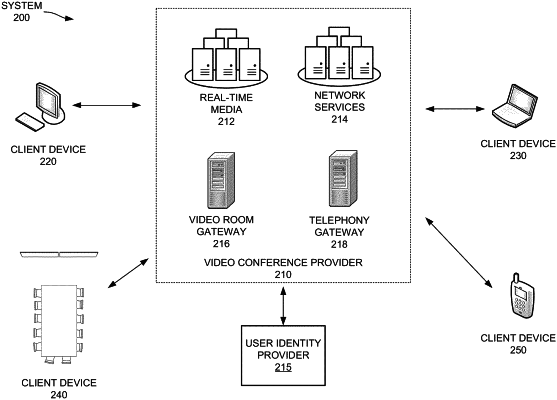
|
1. A computer-implemented method, comprising:
accessing, by a computing device of a video conference provider system, audio information comprising an audio stream from a client device;
providing, by the computing device, a first audio segment from the audio stream to a language identification process of the computing device comprising a machine learning model that is trained to identify a language of a plurality of languages within recorded speech, wherein the plurality of languages comprises an unidentified language indicator and one or more languages, wherein the language identification process assigns a first confidence score to the first audio segment;
identifying, by the language identification process of the computing device, a first identified-language corresponding to the first audio segment based at least in part on the first confidence score exceeding a confidence threshold;
initiating, by the computing device, a change timer in response to identifying the first identified-language, wherein the confidence threshold is an increased confidence threshold until a conclusion of the change timer; and
before the conclusion of the change timer:
providing, by the computing device, a second audio segment from the audio stream to the language identification process of the computing device, wherein the language identification process assigns a second confidence score to the second audio segment; and
identifying, by the language identification process of the computing device, a second identified-language corresponding to the second audio segment based at least in part on the second confidence score exceeding the increased confidence threshold, wherein the first identified-language and the second identified-language are different languages.
|