| CPC G16B 40/00 (2019.02) [G06N 3/04 (2013.01); G16B 20/20 (2019.02); G16B 30/10 (2019.02)] | 23 Claims |
|
1. A system for identifying repeat patterns that cause sequence-specific errors in nucleotide sequencing data corresponding to one or more biological samples, comprising:
one or more processors and one or more storage devices storing instructions that, when executed on the one or more processors, cause the one or more processors to implement:
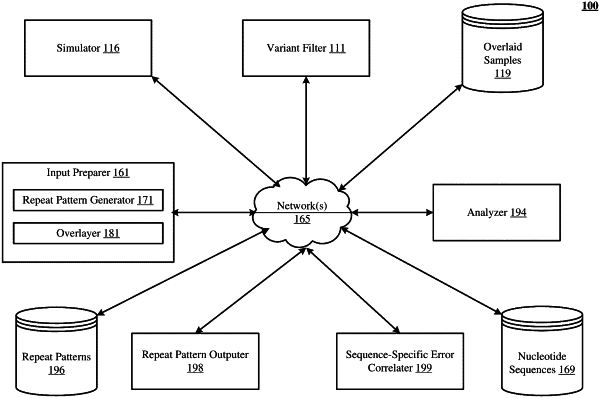
an input preparation subsystem operatively coupled to a sequencer instrument and configured to:
identify nucleotide sequences corresponding to the one or more biological samples;
computationally overlay repeat patterns under test on the nucleotide sequences and produce overlaid samples,
wherein each repeat pattern represents a particular nucleotide composition that has a particular length and appears in an overlaid sample at a particular offset position, wherein each overlaid sample has a target position considered to be a variant nucleotide, and
wherein for each combination of the particular nucleotide composition, the particular length, and the particular offset position, a set of the overlaid samples is computationally generated;
a variant filter subsystem operatively coupled to the sequencer instrument and configured to:
process the overlaid samples through a convolutional neural network and, based on detection of nucleotide patterns in the overlaid samples by convolution filters of the convolutional neural network, generate classification scores for likelihood that the variant nucleotide in each of the overlaid samples is a true variant or a false variant;
a repeat pattern output subsystem operatively coupled to the sequencer instrument and configured to:
output distributions of the classification scores that indicate susceptibility of the variant filter subsystem to false variant classifications resulting from presence of the repeat patterns; and
a sequence-specific error correlation subsystem operatively coupled to the sequencer instrument and configured to:
specify, based on a threshold, a subset of the classification scores as indicative of the false variant classifications, and
classify those repeat patterns which are associated with the subset of the classification scores that are indicative of the false variant classifications as causing the sequence-specific errors in the nucleotide sequencing data corresponding to the one or more biological samples.
|