| CPC G10L 25/48 (2013.01) [G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06V 10/764 (2022.01); G06V 10/774 (2022.01); G10L 15/04 (2013.01); G10L 15/16 (2013.01); G10L 15/22 (2013.01); G10L 15/24 (2013.01); G10L 25/63 (2013.01); G06V 40/174 (2022.01); G06V 40/18 (2022.01)] | 20 Claims |
|
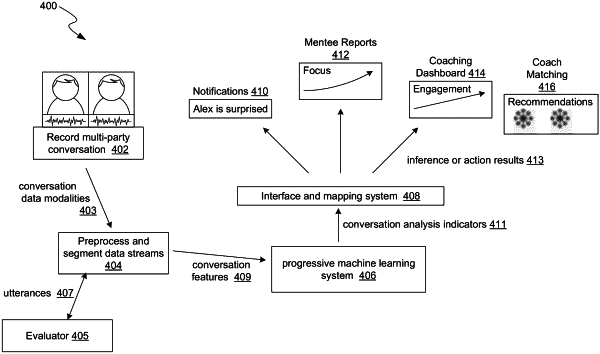
1. A method to generate a conversation analysis, the method comprising:
receiving multiple utterance representations,
wherein each utterance representation represents a portion of a conversation performed by at least two users, wherein one utterance representation represents a particular verbalized statement from one user, and
wherein each utterance representation is associated with one or more of: video data, acoustic data, and text data; and
generating a first utterance output by applying a first utterance representation, that is associated with a first user and that is of the multiple utterance representations, to a machine learning system, wherein generating the first utterance output includes one or more of:
applying video data of the first utterance representation to a first video processing part of the machine learning system to generate first video-based output;
applying acoustic data of the first utterance representation to a first acoustic processing part of the machine learning system to generate first acoustic-based output; and
applying text data of the first utterance representation to a first textual processing part of the machine learning system to generate first text-based output;
wherein the machine learning system includes memory functionality integration such that an internal state of the machine learning system computationally tracks utterances.
|