| CPC G10L 21/02 (2013.01) [G10L 15/02 (2013.01); G10L 15/16 (2013.01); G10L 25/84 (2013.01)] | 14 Claims |
|
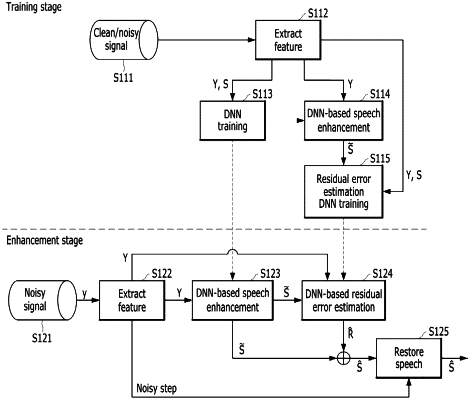
1. An apparatus for a target exaggeration for deep learning-based speech enhancement, comprising:
a signal input unit configured to receive a speech signal comprising a clean signal and a noisy signal;
a feature extraction unit configured to extract a feature of the speech signal;
an expansion unit configured to perform the deep learning-based speech enhancement and target exaggeration based on the extracted feature of the speech signal;
an error estimation unit configured to estimate a target-exaggerated residual error of the speech signal obtained by the deep learning-based speech enhancement; and
a speech restoration unit configured to restore a speech based on the enhanced speech signal and the estimated target-exaggerated residual error,
wherein the apparatus for a target exaggeration for deep learning-based speech enhancement performs, as the target exaggeration for the deep learning-based speech enhancement, at least one target process of a target exaggeration in a cost function of DNN-based speech enhancement in the time-frequency domain approach method, and a target exaggeration with an additional DNN in the time-frequency domain approach method, and a target exaggeration method with an additional DNN in the time domain approach method,
wherein if the target exaggeration with an additional DNN for the DNN-based speech enhancement in the time domain approach method is performed, the apparatus for a target exaggeration for deep learning-based speech enhancement performs training stage of speech enhancement to which the target exaggeration with an additional DNN in the time domain approach method has been applied and enhancement stage of the speech enhancement to which the target exaggeration with an additional DNN in the time domain approach method has been applied,
wherein if the training stage of the speech enhancement to which the target exaggeration with an additional DNN in the time domain approach method is performed,
the signal input unit receives the clean signal and the noisy signal,
the expansion unit performs Conv-TasNet (Convolutional Time-Domain Audio Separation Network) training on the clean signal and the noisy signal by using the SI-SNR (Scale-Invariant Signal-To-Noise Ratio) cost function and performs Conv-TasNet-based speech enhancement by using the noisy signal based on the Conv-TasNet,
the feature extraction unit extracts a speech feature of the clean signal, the noisy signal, and the signal obtained by a Conv-TasNet-based speech enhancement, and
the expansion unit performs DNN training for target-exaggerated residual error estimation based on a speech feature extracted from the clean signal, the noisy signal, and the signal obtained by a Conv-TasNet-based speech enhancement.
|