| CPC G10L 15/22 (2013.01) [G06F 3/165 (2013.01); G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/1815 (2013.01); G10L 15/187 (2013.01); G10L 15/30 (2013.01); G10L 2015/025 (2013.01); G10L 2015/088 (2013.01); G10L 2015/223 (2013.01)] | 13 Claims |
|
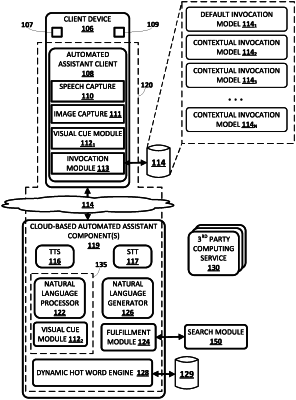
1. A method implemented using one or more processors, comprising:
operating an automated assistant at least in part on one or more devices;
monitoring audio data captured by a microphone for one or more default hot words, wherein detection of one or more of the default hot words triggers transition of the automated assistant from a limited hot word listening state into a speech recognition state;
detecting, in media content being rendered on one or more of the devices, a question;
in response to detecting the question in the media content, performing a web search to determine a likely answer to the question;
based on the answer, activating one or more content-specific hot words that are pertinent to the answer;
without detecting of one or more of the default hot words or transitioning the automated assistant into the speech recognition state, detecting one or more of the content-specific hot words in an utterance captured by the microphone; and
in response to detecting one or more of the content-specific hot words in the utterance captured by the microphone, providing natural language output containing feedback about the utterance.
|