| CPC G10L 15/22 (2013.01) [G06F 3/167 (2013.01); G10L 15/18 (2013.01); G10L 15/28 (2013.01); G10L 2015/223 (2013.01)] | 15 Claims |
|
1. A method implemented by one or more processors, the method comprising:
performing speech-to-text processing on data that characterizes a spoken utterance provided by a user in furtherance of causing an automated assistant to perform an action, wherein the spoken utterance includes natural language content and is received via an automated assistant interface of a computing device that is connected to a display panel;
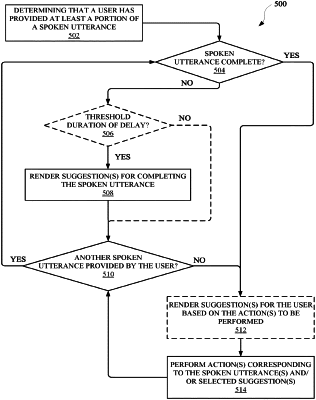
determining, based on performing the speech-to-text processing on the data that characterizes the spoken utterance, whether the spoken utterance is complete, which includes at least determining whether the natural language content is void of one or more parameter values for controlling a function associated with the action; and
when the spoken utterance is determined to be incomplete:
determining, based on contextual data that is accessible via the computing device, contextual data that characterizes a context in which the user provided the spoken utterance to the automated assistant interface,
determining, based on the contextual data that characterizes the context in which the user provided the spoken utterance, a time to present one or more suggestions that are each for a corresponding additional spoken utterance that supplements the spoken utterance, via the display panel, wherein the contextual data indicates that the user previously provided a separate spoken utterance to the automated assistant in the context, and
causing, based on determining the time to present the one or more suggestions via the display panel, the display panel of the computing device to provide one or more suggestion elements,
wherein the one or more suggestion elements include a particular suggestion element that provides, via the display panel, other natural language content that, when spoken by the user to the automated assistant interface, causes the automated assistant to operate in furtherance of completing the action.
|