| CPC G10L 15/20 (2013.01) [G06N 3/08 (2013.01); G10L 15/16 (2013.01); G10L 15/22 (2013.01); G10L 21/0308 (2013.01); G10L 25/18 (2013.01)] | 26 Claims |
|
1. A method for Convolutional Neural Network (CNN) based speech source separation, wherein the method includes:
providing multiple frames of a time-frequency transform of an original noisy speech signal;
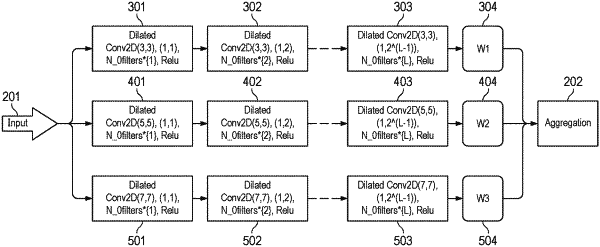
inputting the time-frequency transform of said multiple frames into an aggregated multi-scale CNN having a plurality of parallel convolution paths, wherein each parallel convolution path, out of the plurality of parallel convolution paths of the CNN, includes a cascade of L convolution layers, wherein L is a natural number>1, wherein an l-th layer among the L layers has Nl filters with l=1 . . . L, wherein the filter size of the filters is different between different parallel convolution paths and wherein the filter size of the filters is the same within each parallel convolution path;
extracting and outputting, by each parallel convolution path, features from the input time-frequency transform of said multiple frames;
obtaining an aggregated output of the outputs of the parallel convolution paths; and
generating an output mask for extracting speech from the original noisy speech signal based on the aggregated output.
|