| CPC G10L 15/16 (2013.01) [G06N 3/08 (2013.01); G10L 15/05 (2013.01); G10L 15/063 (2013.01); G10L 15/22 (2013.01); G10L 2015/0635 (2013.01)] | 14 Claims |
|
1. A method implemented by one or more processors, the method comprising:
receiving audio data comprising a sequence of segments and capturing an utterance spoken by a human speaker;
for each of the segments, and in the sequence:
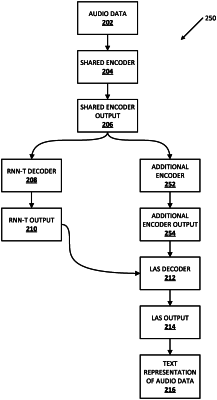
processing the segment using a first-pass portion of an automatic speech recognition (“ASR”) model to generate recurrent neural network transformer (“RNN-T”) output, wherein processing the segment using the first-pass portion of the ASR model comprises:
processing the segment using a shared encoder portion to generate shared encoder output,
adding the shared encoder output as the next item in a shared encoder buffer, and
processing the shared encoder output using a RNN-T decoder portion to generate a corresponding portion of RNN-T output;
determining one or more first-pass candidate text representations of the utterance based on the RNN-T output;
determining the human speaker has finished speaking the utterance;
in response to determining the human speaker has finished speaking the utterance:
processing the shared encoder output from the shared encoder buffer using an additional encoder to generate additional encoder output;
generating listen attend spell (“LAS”) output based on processing, using a second-pass LAS decoder portion of the ASR model, the additional encoder output along with at least one of (a) the RNN-T output or (b) the one or more first-pass candidate text representations of the utterance; and
generating a final text representation of the utterance based on the LAS output.
|