| CPC G10L 15/063 (2013.01) [G06N 3/045 (2023.01); G10L 15/16 (2013.01); G10L 15/183 (2013.01)] | 20 Claims |
|
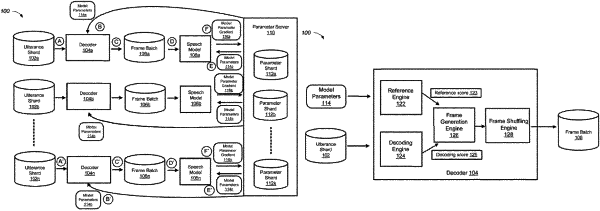
1. A computer-implemented method executed on data processing hardware that causes the data processing hardware to perform operations comprising:
receiving a current set of parameter values for a neural network model executable on the data processing hardware;
obtaining training utterances each comprising one or more predetermined words spoken by a speaker;
processing the training utterances using the current set of parameter values for the neural network model;
determining updated parameter values for the neural network model based on the processing of the training utterances; and
performing stochastic gradient descent optimization to determine corresponding model parameter gradients for the neural network model based on differences between the current set of parameter values and the updated parameter values for the neural network model.
|