| CPC G10L 13/047 (2013.01) [G06N 3/08 (2013.01); G10L 13/08 (2013.01); G10L 25/18 (2013.01); G10L 25/21 (2013.01); G10L 25/30 (2013.01); G10L 25/51 (2013.01)] | 24 Claims |
|
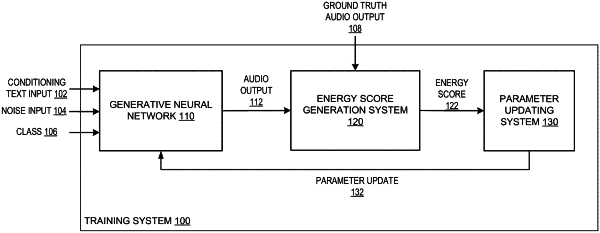
1. A method of training a neural network having a plurality of parameters and configured to generate audio outputs that define audio examples using conditioning text inputs,
wherein the neural network is configured to receive a generative input comprising a conditioning text input and a noise input and to process the network input to generate an audio output that comprises respective audio samples at each of a plurality of output time steps, and
wherein the method comprises:
obtaining a training example comprising a training conditioning text input and a corresponding ground-truth audio output;
generating a plurality of predicted audio outputs for the training example by, for each of a plurality of noise inputs, processing a training generative input comprising the training conditioning text input and the noise input using the neural network in accordance with current values of the parameters to generate respective predicted audio output;
determining an estimated energy score characterizing a distance between the ground-truth audio output and the plurality of predicted audio outputs, comprising:
computing, for a first predicted audio output of the plurality of predicted audio outputs, a distance between the first predicted audio output and the ground-truth audio output according to a distance metric, comprising computing a distance between a spectrogram corresponding to the first predicted audio output and a spectrogram corresponding to the ground-truth audio output according to a spectrogram distance metric; and
computing, for the first predicted audio output and a second predicted audio output of the plurality of predicted audio outputs, a distance between the first predicted audio output and the second predicted audio output according to the distance metric, comprising computing a distance between a spectrogram corresponding to the first predicted audio output and a spectrogram corresponding to the second predicted audio output according to the spectrogram distance metric; and
determining an update to the current values of the parameters according to the estimated energy score.
|