| CPC G10L 13/02 (2013.01) [G06F 3/165 (2013.01); G06N 5/02 (2013.01); G06N 20/00 (2019.01); G10K 15/08 (2013.01); G10L 13/033 (2013.01); G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/065 (2013.01); G10L 21/0224 (2013.01); G10L 25/03 (2013.01); H04S 7/30 (2013.01); H04S 7/302 (2013.01); H04S 7/303 (2013.01)] | 20 Claims |
|
1. A computer-implemented method, executed on a computing device, comprising:
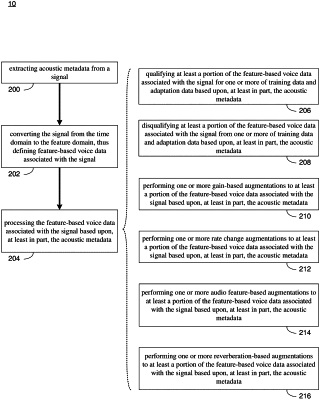
receiving feature-based voice data associated with a first acoustic domain, the first acoustic domain defined, at least in part, by signal processing characteristics associated with a microphone associated with the first acoustic domain, wherein receiving feature-based voice data includes extracting acoustic metadata from a signal, the acoustic metadata describing an acoustic characteristic of at least a portion of the feature-based voice data including one or more of presence of a speech component, speaking rate, and reverberation level;
qualifying at least a portion of the feature-based voice data for one or more of training data and adaptation data based upon, at least in part, the acoustic metadata, including:
receiving one or more constraints associated with processing feature-based voice data; and
comparing the one or more constraints to at least a portion of the acoustic metadata to determine whether the feature-based voice data is qualified for a particular task;
receiving a selection of a target acoustic domain, the target acoustic domain defined, at least in part, by a characteristic associated with a microphone associated with the target acoustic domain;
receiving one or more data augmentation characteristics; and
generating, via a machine learning model, one or more augmentations of the feature-based voice data based upon, at least in part, the feature-based voice data, selected target acoustic domain, and the one or more data augmentation characteristics.
|