| CPC G06V 20/40 (2022.01) [G06V 20/20 (2022.01); H04N 23/661 (2023.01)] | 18 Claims |
|
1. A computer-implemented method comprising:
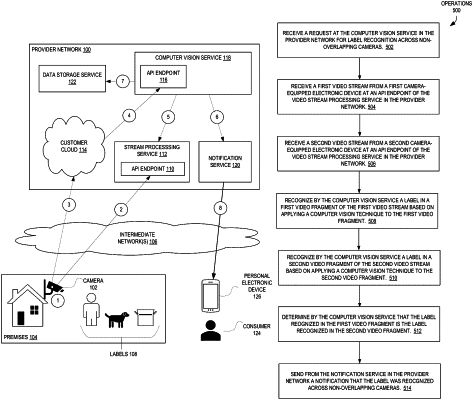
receiving, via an application program interface (API) endpoint of a computer vision service in a provider network, a request for label recognition across non-overlapping cameras, the request for label recognition across non-overlapping cameras comprising an identifier of a first video stream and comprising an identifier of a second video stream;
receiving, via an application programming interface (API) endpoint of a stream processing service in a provider network, the first video stream from a first camera-equipped electronic device having a first field of view;
receiving, via an application programming interface (API) endpoint of the stream processing service in the provider network, the second video stream from a second camera-equipped electronic device having a second field of view that does not overlap the first field of view;
recognizing, by the computer vision service in the provider network, a label in a first video fragment of the first video stream based on applying a computer vision technique to the first video fragment;
recognizing, by the computer vision service in the provider network, a label in a second video fragment of the second video stream based on applying a computer vision technique to the second video fragment;
identifying, by the computer vision service in the provider network, that the label recognized in the first video fragment is the label recognized in the second video fragment; and
sending, from a notification service in the provider network, a notification that the label was recognized in video captured by the first camera-equipped electronic device and in video captured by the second camera-equipped electronic device;
wherein:
the notification comprises a first reference to a first video frame of the first video fragment,
the notification comprises a second reference to a second video frame of the second video fragment,
the first video frame is annotated with a first bounding box encompassing the label recognized in the first video fragment,
the second video frame is annotated with a first bounding box encompassing the label recognized in the second video fragment, and
the first bounding box and the second bounding box are each associated with a same text label that indicates that the label recognized in the first video fragment is the label recognized in the second video fragment.
|