| CPC G06V 10/764 (2022.01) [G06V 10/774 (2022.01)] | 19 Claims |
|
1. A non-transitory computer readable medium storing a software program comprising data and computer implementable instructions that when executed by at least one processor cause the at least one processor to perform operations for attributing aspects of generated visual contents to training examples, the operations comprising:
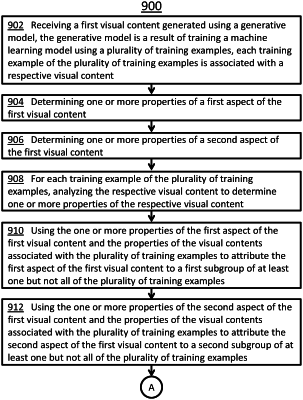
receiving a first visual content generated using a generative model, the generative model is a result of training a machine learning model using a plurality of training examples, each training example of the plurality of training examples is associated with a respective visual content;
determining one or more properties of a first aspect of the first visual content;
determining one or more properties of a second aspect of the first visual content;
for each training example of the plurality of training examples, analyzing the respective visual content to determine one or more properties of the respective visual content;
using the one or more properties of the first aspect of the first visual content and the properties of the visual contents associated with the plurality of training examples to attribute the first aspect of the first visual content to a first subgroup of at least one but not all of the plurality of training examples;
using the one or more properties of the second aspect of the first visual content and the properties of the visual contents associated with the plurality of training examples to attribute the second aspect of the first visual content to a second subgroup of at least one but not all of the plurality of training examples;
determining that the at least one visual content associated with the training examples of the first subgroup are associated with a first at least one source;
determining that the at least one visual content associated with the training examples of the second subgroup are associated with a second at least one source;
for each source of the first at least one source, updating a data-record associated with the source based on the attribution of the first aspect of the first visual content; and
for each source of the second at least one source, updating a data-record associated with the source based on the attribution of the second aspect of the first visual content,
wherein the training of the machine learning model to obtain the generative model includes a first training step and a second training step, the first training step uses a third subgroup of the plurality of training examples to obtain an intermediate model, the second training step uses a fourth subgroup of the plurality of training examples and uses the intermediate model for initialization to obtain the generative model, the fourth subgroup differs from the third subgroup, and wherein the operations further comprise:
comparing a result associated with the first visual content and the intermediate model with a result associated with the first visual content and the generative model; and
for each training example of the fourth subgroup, determining whether to attribute the first aspect of the first visual content to the respective training example based on a result of the comparison.
|