| CPC G06T 7/579 (2017.01) [B60W 60/001 (2020.02); B60W 60/0027 (2020.02); G06N 3/08 (2013.01); G06T 7/248 (2017.01); G06T 7/269 (2017.01); G06T 7/337 (2017.01); G06T 7/75 (2017.01); G06V 10/462 (2022.01); G06V 10/764 (2022.01); G06V 10/82 (2022.01); G06V 20/56 (2022.01); G06V 20/64 (2022.01); B60W 2420/42 (2013.01); G06T 2207/10016 (2013.01); G06T 2207/10028 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/30241 (2013.01); G06T 2207/30248 (2013.01); G06T 2207/30252 (2013.01)] | 15 Claims |
|
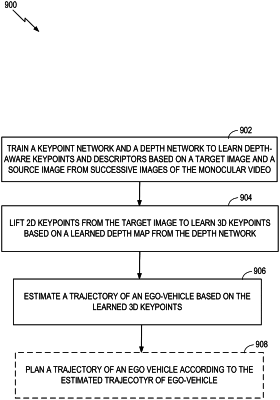
1. A method for learning depth-aware keypoints and associated descriptors from monocular video for monocular visual odometry, comprising:
training a keypoint network and a depth network to learn the depth-aware keypoints and the associated descriptors based on a target image and a context image from successive images of the monocular video by computing a corresponding set of initial keypoints from the target image and initial keypoints from the context image, determining an ego-motion between the corresponding set of initial keypoints from the target image and the initial keypoints from the context image, and computing updated keypoints from the target image based on the determined ego-motion to learn a synthesized target image;
lifting 2D keypoints from the synthesized target image to learn 3D keypoints based on a learned depth map from the depth network;
estimating an estimated trajectory of an autonomous ego vehicle based on the learned 3D keypoints; and
planning a planned trajectory of the autonomous ego vehicle according to the estimated trajectory of the autonomous ego vehicle.
|