| CPC G06T 19/20 (2013.01) [G06F 18/2148 (2023.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06N 3/044 (2023.01); G06N 3/047 (2023.01); G06N 3/084 (2013.01); G06N 3/088 (2013.01); G06T 2219/2016 (2013.01); G06V 10/82 (2022.01); G06V 40/20 (2022.01)] | 16 Claims |
|
1. An apparatus comprising:
a memory configured to store a machine-learning model; and
a processor configured to:
receive, via a sensor of the apparatus, an external input from a user to control a virtual object displayed in a virtual space by the apparatus;
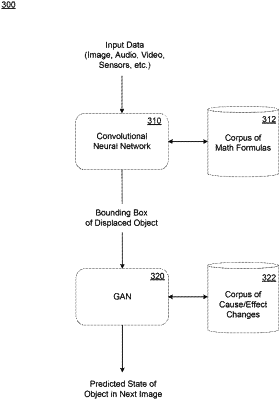
send a message comprising an identification of a type of the external input and a value of the external input, as measured by the sensor, to a machine-learning model, wherein the machine-learning model comprises a convolutional neural network (CNN) layer and a generative adversarial network (GAN),
identify by the CNN layer a first bounding box corresponding to an approximate location of the virtual object in a current image of the virtual space before the external input is applied and a second bounding box corresponding to a predicted location of the virtual object in a next image of the virtual space after the external input is applied,
receive by the GAN the second bounding box from the CNN layer,
predict a location of the virtual object in the next image based on the external input of the user and the second bounding box;
and
move the virtual object in the virtual space based on the predicted location of the virtual object in the next image.
|