| CPC G06Q 10/06375 (2013.01) [G06Q 10/06395 (2013.01); G06Q 50/02 (2013.01)] | 27 Claims |
|
1. A method, the method comprising:
choosing a plurality of components of a soybean plant;
acquiring first analytical data of each of the plurality of chosen components of a leaf sample collected from a plurality of first soybean plants;
constructing, by a processor, a first yield prediction model in a form of a machine learning model using the first analytical data of each of the plurality of chosen components of the leaf sample collected from the plurality of first soybean plants;
calculating a variable importance in projection (VIP) value for each of the plurality of chosen components of the leaf sample collected from the plurality of first soybean plants with respect to the first yield prediction model;
selecting a subset of the plurality of chosen components of the leaf sample collected from the plurality of first soybean plants based upon the VIP values, the subset of the plurality of chosen components of the leaf sample collected from the plurality of first soybean plants including fewer components than the plurality of chosen components;
constructing, by the processor, a second yield prediction model in a form of a machine learning model using the first analytical data of each of the components in the subset of the plurality of chosen components which includes fewer components than the plurality of chosen components;
acquiring second analytical data of the components of the subset of the plurality of chosen components which includes fewer components than the plurality of chosen components from a leaf sample collected from a second soybean plant from a field;
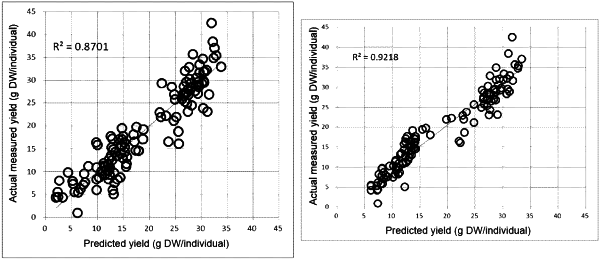
predicting a soybean yield using the second analytical data and the second yield prediction model, which was constructed using the first analytical data of each of the components in the subset of the plurality of chosen components which includes fewer components than the plurality of chosen components;
selecting a material for the field from which the second soybean plant came based upon the predicted soybean yield;
comparing an actual soybean yield of the second soybean plant and the predicted soybean yield; and
optimizing the second yield prediction model based upon a result of the comparison of the actual soybean yield and the predicted soybean yield.
|