| CPC G06N 3/08 (2013.01) [G06N 3/047 (2023.01); G10L 25/51 (2013.01)] | 20 Claims |
|
1. A computer-implemented method performed by a data processing apparatus, the method comprising:
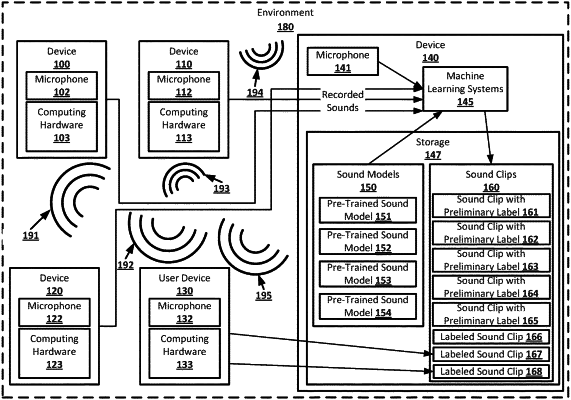
receiving, on a computing device in an environment, from devices in the environment, sound recordings made of sounds in the environment;
determining, by the computing device, preliminary labels for the sound recordings using pre-trained sound models, wherein each of the preliminary labels has an associated probability;
generating, by the computing device, sound clips with preliminary labels based on the sound recordings that have determined preliminary labels whose associated probability is over a high-recall threshold for the one of the pre-trained sound models that determined the preliminary label;
sending, by the computing device, the sound clips with preliminary labels to a user device;
presenting, by the user device, the sounds clips with the preliminary labels, wherein:
a first sound clip is selected by a user as matching its preliminary label; and
a second sound clip is provided a second label, differing from its preliminary label, by the user;
receiving, by the computing device, labels for the sound clips from the user device, wherein:
a first label for the first sound clip matches its preliminary label; and
the second label for the second sound clip differs from its preliminary label;
generating, by the computing device, training data sets for the pre-trained sound models using the labeled sound clips; and
training the pre-trained sound models using the training data sets to generate localized sound models.
|