| CPC G06N 3/063 (2013.01) [G06N 3/047 (2023.01); G06N 3/08 (2013.01); G06V 10/70 (2022.01); G06V 10/82 (2022.01); G06V 10/454 (2022.01)] | 17 Claims |
|
1. A neural network device comprising:
a quantization parameter calculator configured to quantize parameters of a neural network that is pre-trained, so that the quantized parameters are of mixed data types; and
a processor configured to apply the quantized parameters to the neural network,
wherein the quantization parameter calculator is further configured to:
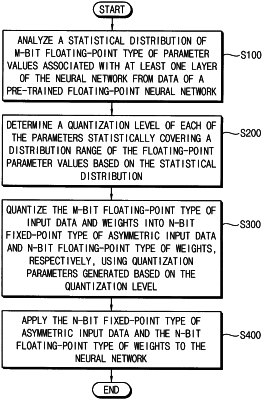
analyze a statistical distribution of parameter values of an M-bit floating-point type, the parameter values being associated with at least one layer of the neural network, M being a natural number greater than three;
obtain a quantization level of each of the parameters statistically covering a distribution range of the parameter values, based on the analyzed statistical distribution; and
quantize input data and weights of the M-bit floating-point type into asymmetric input data of an N-bit fixed-point type and weights of an N-bit floating-point type, using quantization parameters that are obtained based on the obtained quantization level of each of the parameters, N being a natural number greater than one and less than M,
wherein the quantization parameter calculator is further configured to:
obtain a first step size that corresponds to a first gap between the obtained quantization level of each of the parameters, by using a statistical maximum value and a statistical minimum value of the parameter values, and the obtained quantization level of each of the parameters, wherein the input data is quantized based on the obtained first step size and a first zero point, the first zero point indicating a zero value of the input data of the M-bit floating-point type;
obtain a second step size that corresponds to a second gap between a quantization level of an output data that is obtained by performing a node operation of the input data and the weights of the M-bit floating-point type, wherein the output data is quantized based on the obtained second step size and a second zero point, the second zero point indicating a zero value of the output data;
obtain a new weight, based on the obtained first step size and the obtained second step size; and
obtain a new bias based on a bias that is not quantized, the obtained new weight, the obtained first zero point and the obtained second step size, and
wherein the processor is further configured to obtain the quantized output data by performing a node operation on the quantized input data and the new weight and adding the new bias.
|