| CPC G06N 3/0464 (2023.01) [G06F 30/327 (2020.01); G06F 30/34 (2020.01); G06F 30/347 (2020.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/047 (2023.01); G06N 3/084 (2013.01); G06N 20/00 (2019.01); G06N 20/10 (2019.01); G06F 9/44505 (2013.01); G06F 13/4022 (2013.01); G06F 15/7817 (2013.01); G06F 2115/02 (2020.01); G06F 2115/08 (2020.01); G06N 3/04 (2013.01); G06N 3/063 (2013.01); G06N 3/08 (2013.01); G06N 7/01 (2023.01)] | 18 Claims |
|
1. A hardware accelerator engine that supports efficient mapping of convolutional stages of deep neural network algorithms, the hardware accelerator engine comprising:
a stream switch having first and second stream switch input ports and a plurality of stream switch output ports, the stream switch being configurable during run time to selectively connect each of the stream switch input ports to any one or more of the stream switch output ports; and
a plurality of convolution accelerators coupled together via the stream switch, each one of the plurality of convolution accelerators including:
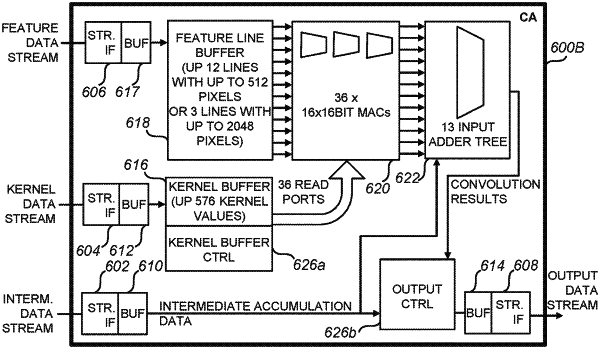
a kernel buffer;
a feature line buffer; and
a plurality of multiply-accumulate (MAC) units arranged to multiply and accumulate data received from both the kernel buffer and the feature line buffer, wherein lines of the feature line buffer are configured to provide columns of feature line data to MAC units of the plurality of MAC units,
wherein a first one of the convolution accelerators is operable, during run time and based on information processed from one or both of the kernel buffer and the feature line buffer during run time by the first convolution accelerator, to selectively reconfigure the feature line buffer of the first convolution accelerator from a first configuration in which a first line of the feature line buffer is coupled to a first MAC unit of the plurality of MAC units to a second configuration in which a second line of the feature line buffer is coupled to the first MAC unit of the plurality of MAC units.
|