| CPC G06N 20/00 (2019.01) | 20 Claims |
|
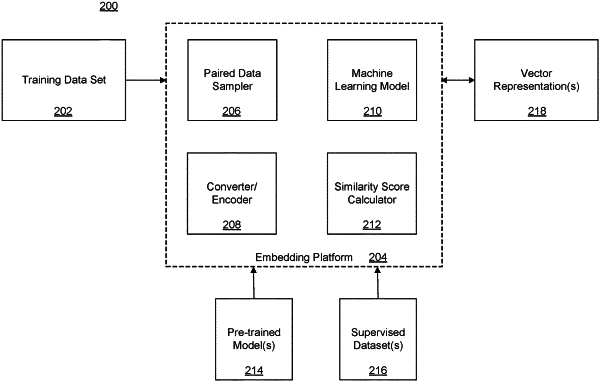
1. A computer-implemented method for generating a semantic similarity based on a vector representation, the method comprising:
receiving a training data set extracted from unlabeled data, the training data set including a plurality of paired data samples corresponding to positive example pairs, each positive example pair including a first data unit and a second data unit, wherein the first data unit and the second data unit are located within a predetermined distance threshold of each other within the unlabeled data;
converting the paired data samples corresponding to the positive example pairs into at least one first vector of a vector representation;
accessing one or more negative example pairs within the training data set to contrast against the positive example pairs;
converting the one or more negative example pairs into one or more second vectors of the vector representation; and
training a machine learning model to generate additional vectors of the vector representation, wherein the training comprises:
initializing the machine learning model with one or more pre-trained models, the one or more pre-trained models comprising generative language models; and
training the machine learning model using contrastive training based on: the at least one first vector of the vector representation and the one or more second vectors of the vector representation;
receiving a query for semantic similarity, the query including a natural language input; and
generating, with the machine learning model and according to an embedding space, a semantic similarity result in response to the query.
|