| CPC G06F 40/56 (2020.01) [G06F 40/226 (2020.01); G06F 40/30 (2020.01)] | 20 Claims |
|
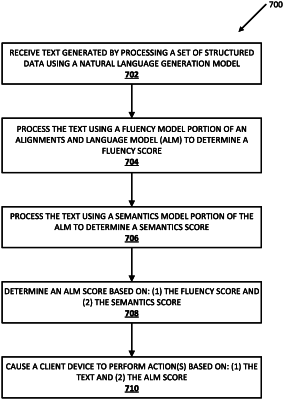
14. A method implemented by one or more processors, the method comprising:
receiving a plurality of instances of natural language text based on a set of structured data, wherein each instance of natural language text is generated by processing the set of structured data using at least one natural language generation model;
processing the plurality of instances of natural language text using an alignments and language model (ALM) to automatically generate a plurality of corresponding ALM scores, wherein processing each instance of natural language text using the ALM comprises:
processing the instance of natural language text using a fluency model portion of the ALM to generate a fluency score, wherein the fluency score is an evaluation of the fluency and the grammar of the instance of natural language text;
processing the instance of natural language text and the set of structured data using a semantics model portion of the ALM to generate a semantics score, wherein the semantics score evaluates the content of the instance of natural language text based on the corresponding set of structured data;
determining the corresponding ALM score based on the fluency score and the semantics score;
selecting one or more instances of natural language text from the plurality of instances of natural language text based on the corresponding ALM scores;
for each of the one or more selected instances of natural language text, determining a corresponding audio waveform based on the instance of natural language text; and
causing a client device to render output based on each of the corresponding audio waveforms corresponding to the one or more selected instances of natural language text.
|