| CPC G06F 21/6254 (2013.01) [G06F 40/284 (2020.01)] | 22 Claims |
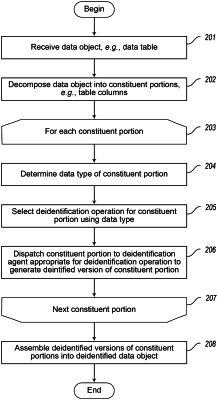
|
1. One or more instances of computer-readable media collectively having contents configured to cause a computing system to perform a method, the method comprising:
receiving a data object;
identifying in the data object a plurality of constituent portions;
selecting a first constituent portion of the data object containing one or more free text strings;
in a first computing mechanism:
for each free text string:
subjecting the free text string to a trained machine learning model to predict occurrence within the free text string of a personal identifier based on predicting occurring within of certain named entities;
in a repeatable manner, generating a substitute personal identifier from the predicted personal identifier;
creating a copy of the free text string;
in the free text string copy, replacing the predicted personal identifier with the generated substitute personal identifier;
after the replacement, collecting the free text string copies in a modified version of the first constituent portion;
selecting a second constituent portion of the data object distinct from the first constituent portion containing data items of a type other than free text strings;
in a second computing mechanism distinct from the first computing mechanism:
for each data item:
in a repeatable manner, generating a substitute data item from the data item;
collecting the substitute data items in a modified version of the second constituent portion; and
assembling the modified version of the first constituent portion and modified version of the second constituent portion into a modified version of the data object,
wherein the subjecting subjects the free text string to a plurality of trained machine learning models in sequence to collectively predict occurrence within the free text string of a personal identifier based on predicting occurring within of certain named entities.
|