| CPC G06F 18/2431 (2023.01) | 3 Claims |
|
1. A data classification system comprising:
a memory configured to store instructions; and
a processor configured to execute the instructions to:
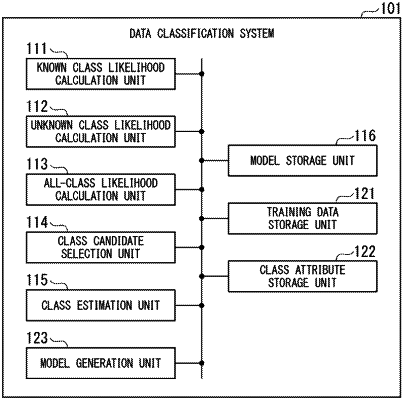
calculate, for each of a plurality of known classes that appear in training data on which a machine learning model is trained, a known class likelihood that target data belongs to the known class among all the known classes, using the machine learning model;
calculate, for each of a plurality of unknown classes that do not appear in the training data on which the machine learning model is trained, a similarity of each known class to the unknown class;
calculate, for each unknown class, an unknown class likelihood that the target data belongs to the unknown class among all the unknown classes, based on the known class likelihood and the similarity of each known class to the unknown class;
select, as a plurality of candidate classes, one or more of the known classes and one or more of the unknown classes based on the known class likelihood of each known class and the unknown class likelihood of each unknown class,
wherein the selected known classes are a first number of the known classes for which the known class likelihood is highest, or are the known classes for which the known class likelihood is greater than a first threshold, and
wherein the selected unknown classes are a second number of the unknown classes for which the unknown class likelihood is highest, or are the unknown classes for which the unknown class likelihood is greater than a second threshold;
calculate, for each candidate class, an all-class likelihood that the target data belongs to the candidate class among all the candidate classes; and
estimate the candidate class to which the target data belongs based on the all-class likelihood of each candidate class.
|