| CPC G06F 18/23 (2023.01) [G06F 16/285 (2019.01); G06F 18/22 (2023.01)] | 10 Claims |
|
1. A method of organizing data, comprising:
providing a plurality of data points including a plurality of attributes;
creating a plurality of categories for the data points each based on a respective one of the plurality of attributes of the data points;
establishing a plurality of neighborhoods for the data points based on the categories, wherein each neighborhood comprises a subset of the plurality of categories;
inserting each of the plurality of data points into one of the plurality of neighborhoods to produce an unordered, unclustered dataset;
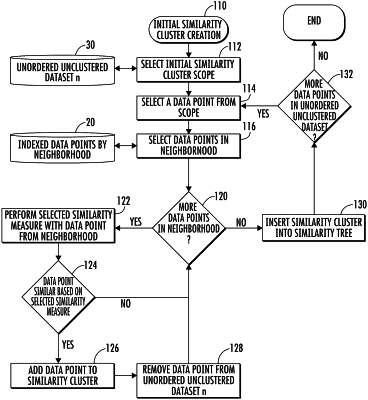
creating a similarity cluster comprising clustering steps of:
selecting a similarity cluster scope comprising a single selected neighborhood;
selecting a representative data point corresponding to the similarity cluster scope from the selected neighborhood;
selecting other data points in the selected neighborhood of the representative data point;
performing a similarity measure on the other data points comprising a step of comparing to determine whether each of the other data points are similar data points that include any of the plurality of attributes of the representative data point;
inserting the similar data points together with the representative data point to create the similarity cluster corresponding to the similarity measure and removing the similar data points from the unordered, unclustered dataset; and inserting the similarity cluster into a similarity tree organized dataset having other similarity clusters; and
repeating the clustering steps to create at least one additional similarity cluster including additional data points from the unordered, unclustered dataset until all data points belong to a similarity cluster, wherein at least one additional similarity cluster is inserted into the similarity tree organized dataset.
|