| CPC G06F 18/2148 (2023.01) [G06F 18/2163 (2023.01); G06F 40/00 (2020.01)] | 20 Claims |
|
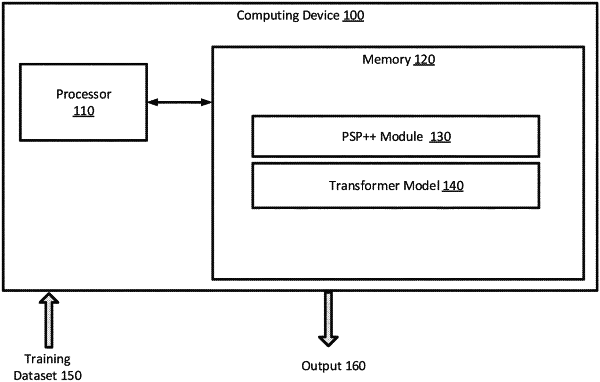
1. A method for pre-training a transformer model, the method comprising:
dividing the transformer model stored in memory into a held-out model and a main model, wherein the held-out model comprises attention heads of the transformer model from a portion of a predefined number of lower layers of the transformer model;
performing, using a training dataset, a forward pass on the held-out model, the forward pass determines self-attention hidden states of the held-out model at corresponding layers in the predefined number of lower layers;
performing, using the training dataset, a forward pass on the main model, wherein the forward pass comprises:
determining self-attention hidden states of the main model at a corresponding layer;
concatenating the self-attention hidden states of the main model at the corresponding layer with the self-attention hidden states of the held-out model at the corresponding layer, wherein the concatenated self-attention hidden states are inputs to a layer subsequent to the corresponding layer of the main model;
performing, a backward pass on the held-out model, the backward pass determines a loss of the held-out model;
performing, a backward pass on the main model, the backward pass determines a loss of the main model; and
updating parameters of the held-out model based on the loss of the held-out model and parameters of the main model based on the loss of the main model.
|