| CPC G06F 17/16 (2013.01) [G06F 7/523 (2013.01); G06F 17/12 (2013.01)] | 12 Claims |
|
1. A method comprising:
storing in main memory at least a portion of a left matrix A and a right matrix B, wherein matrix A has m rows and n columns, and matrix B has n rows and p columns;
wherein said main memory is coupled to a multi-core processor comprising a plurality of core processors and a plurality of scratchpad memories, wherein each scratchpad memory of said plurality of scratch memories is accessible and private to one respective core processor of said plurality of core processors, wherein said plurality of scratchpad memories include a particular scratchpad memory that accessible and private to a particular core processor of said plurality of core processors;
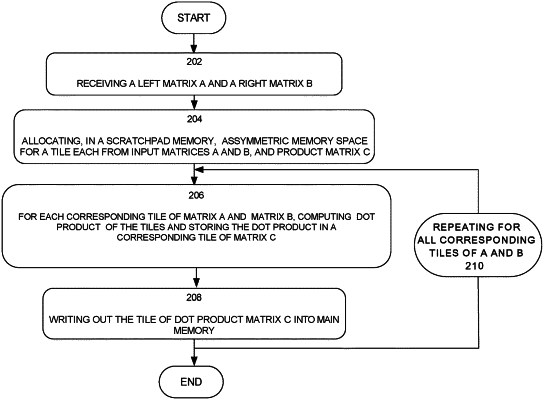
allocating at least space of size T in the particular scratchpad memory to each of a tile of matrix A and a tile of matrix C,
after allocating at least space of size T in the particular scratchpad memory to each of a tile of matrix A and a tile of matrix C, allocating remaining space in the particular scratchpad memory to a tile of matrix B;
said particular core processor performing a dot product matrix multiplication involving said one or more tiles of matrix A and corresponding said one or more tiles of matrix B, wherein dot product values are stored in corresponding said one or more tiles of matrix C, wherein performing said dot product matrix multiplication includes accessing, in said particular scratchpad memory:
said one or more tiles of matrix A,
corresponding said one or more tiles of matrix B, and
corresponding said one or more tiles of matrix C to store said dot product values;
writing out the dot product values into main memory.
|