| CPC G05D 1/0274 (2013.01) [B25J 9/161 (2013.01); B25J 9/1653 (2013.01); B25J 9/1697 (2013.01); B25J 13/089 (2013.01); G06V 10/235 (2022.01); G06V 10/454 (2022.01); G06V 10/764 (2022.01); G06V 10/82 (2022.01); G06V 10/95 (2022.01); G06V 20/10 (2022.01); G06V 20/52 (2022.01); G06V 20/68 (2022.01)] | 21 Claims |
|
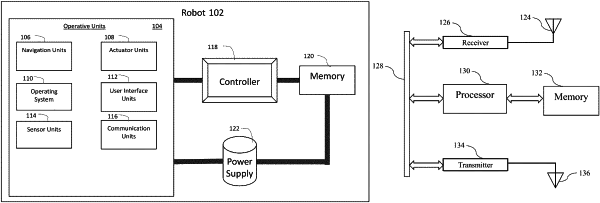
1. A server system, comprising:
at least one robot coupled to the server system;
a plurality of models coupled to the server system configured to identify features within imagery with an associated confidence; and
a centralized server comprising one or more processors configured to execute computer readable instructions that cause at least one of the one or more processors to:
receive at least one image from a sensor on at least one robot coupled to the at least one processor, each of the at least one images associated with a corresponding location comprising a local environment in which the robot is navigating during acquisition of the image, wherein each of the at least one image comprises feature data;
select, based at least in part on the corresponding location of each of the at least one image, at least one model from a plurality of models coupled to the at least one processor and communicate the feature data to the selected at least one model, the corresponding location of each of the at least one images being on a first computer readable map produced by the at least one robot, wherein each of the plurality of models is configured to identify the feature data;
cause each of the at least one selected model to identify the feature data within each corresponding image to produce a labeled data output, wherein the labeled output data comprises an identification of one or more features within each image and is selected based in part on a confidence thereof;
determine, based upon the corresponding location of each of the at least one image on the first computer readable map and an image-space position of each respective feature in each corresponding image, a location of the labeled data output within the local environment
generate at least one insight comprising at least in part the location of the labeled data output within the local environment;
construct a second computer readable map based on the location of the at least one insight, wherein the second computer readable map includes a plurality of user selectable locations corresponding to each respective location of the at least one image captured by the robot at the each corresponding location of the at least one images, each of the user selectable locations includes one or more of the at least one insights which correspond to the respective selectable location, the one or more of the at least one insights are displayed on the second computer readable map based on the determined location of the at least one insight; and
provide a device with at least a portion of the second computer readable map when requested by the device.
|