| CPC A61B 5/4803 (2013.01) [A61B 5/7264 (2013.01); A61B 5/7275 (2013.01); G06N 20/00 (2019.01); G10L 25/63 (2013.01); G10L 25/66 (2013.01)] | 15 Claims |
|
1. A computing system, comprising:
at least one processor;
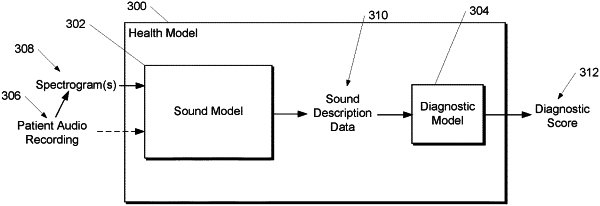
a machine-learned health model comprising:
a sound model, wherein the sound model is trained to receive data descriptive of a patient audio recording and, in response to receipt of the patient audio recording, output sound description data, wherein the sound model comprises a machine-learned audio classification model, and wherein the sound description data comprises an embedding provided by a hidden layer of the machine-learned audio classification model; and
a diagnostic model, wherein the diagnostic model is trained to receive the sound description data, and in response to receipt of the sound description data, output a diagnostic score; and
at least one tangible, non-transitory computer-readable medium that stores instructions that, when executed by the at least one processor, cause the at least one processor to perform operations, the operations comprising:
obtaining the patient audio recording;
inputting data descriptive of the patient audio recording into the sound model;
receiving, as an output of the sound model, the sound description data;
inputting the sound description data into the diagnostic model; and
receiving, as an output of the diagnostic model, the diagnostic score.
|