| CPC H04N 21/4884 (2013.01) [G06F 18/22 (2023.01); G06F 18/253 (2023.01); G06F 18/28 (2023.01); G06V 10/75 (2022.01); G06V 10/772 (2022.01); G06V 20/41 (2022.01); G06V 20/47 (2022.01); G06V 20/635 (2022.01); H04N 5/278 (2013.01); H04N 21/235 (2013.01); H04N 21/23418 (2013.01); H04N 21/435 (2013.01); H04N 21/488 (2013.01); H04N 21/8549 (2013.01)] | 20 Claims |
|
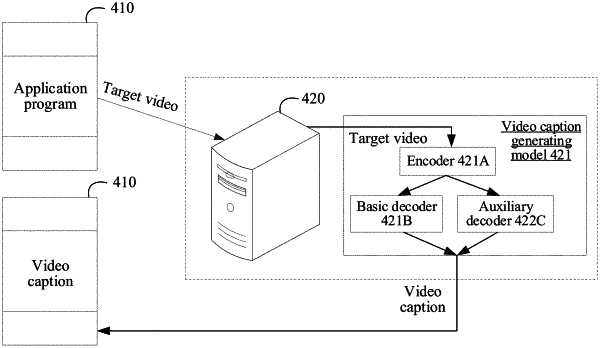
1. A video caption generating method, performed by a computer device, the method comprising:
encoding a target video by using an encoder of a video caption generating model, to obtain a target visual feature of the target video;
decoding the target visual feature by using a basic decoder of the video caption generating model, to obtain a first selection probability corresponding to each candidate word of a plurality of candidate words;
decoding the target visual feature of the target video by using an auxiliary decoder of the video caption generating model, to obtain a second selection probability corresponding to the each candidate word, wherein a memory of the auxiliary decoder stores reference visual context information corresponding to the each candidate word, and the reference visual context information has been generated according to at least one related video corresponding to the each candidate word;
determining a decoded word from the plurality of candidate words according to the first selection probability and the second selection probability of the each candidate word; and
generating a video caption corresponding to the target video according to the decoded word.
|