| CPC G10L 25/66 (2013.01) [G10L 15/16 (2013.01)] | 20 Claims |
|
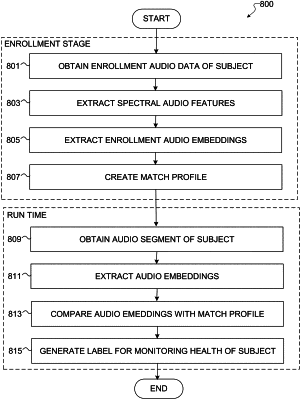
1. A method comprising:
obtaining, by an electronic device, an audio segment comprising one or more audio events of a target subject;
extracting, by the electronic device, audio embeddings from the one or more audio events using an embedding model, the embedding model comprising a machine learning model that is trained to maximize cross-correlation of evaluated audio embeddings generated during training and focus on audio features common across different conditions of subjects such that the embedding model is resilient against changes in condition of the target subject, wherein the embedding model extracts the audio embeddings in order to correlate the one or more audio events with a physiological structure of the target subject;
comparing, by the electronic device, the extracted audio embeddings with a match profile of the target subject, the match profile generated during an enrollment stage;
generating, by the electronic device, a label for the audio segment based on whether or not the extracted audio embeddings match the match profile, wherein the label enables correlation of the audio segment with the target subject for monitoring a health condition of the target subject; and
in response to determining that a distance of the extracted audio embeddings from the match profile is smaller than a specified threshold, updating the match profile using the audio segment.
|