| CPC G10L 15/16 (2013.01) [G06N 3/04 (2013.01); G06N 3/088 (2013.01); G10L 15/063 (2013.01); G10L 15/197 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01)] | 27 Claims |
|
1. A single transformer-transducer model for unifying streaming and non-streaming speech recognition, the single transformer-transducer model comprising:
an audio encoder configured to:
receive, as input, a sequence of acoustic frames; and
generate, at each of a plurality of time steps, a higher order feature representation for a corresponding acoustic frame in the sequence of acoustic frames;
a label encoder configured to:
receive, as input, a sequence of non-blank symbols output by a final softmax layer; and
generate, at each of the plurality of time steps, a dense representation; and
a joint network configured to:
receive, as input, the higher order feature representation generated by the audio encoder at each of the plurality of time steps and the dense representation generated by the label encoder at each of the plurality of time steps; and
generate, at each of the plurality of time steps, a probability distribution over possible speech recognition hypothesis at the corresponding time step,
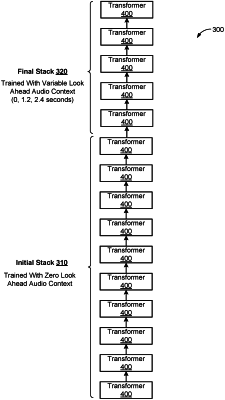
wherein the audio encoder comprises a neural network having a plurality of transformer layers, the plurality of transformer layers comprising:
an initial stack of transformer layers each trained with zero look ahead audio context; and
a final stack of transformer layers each trained with a variable look ahead audio context.
|