| CPC G06V 20/41 (2022.01) [G06F 18/213 (2023.01); G06N 3/045 (2023.01); G06T 7/246 (2017.01); G06T 7/73 (2017.01); G06V 20/46 (2022.01); G06T 2207/10016 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06V 2201/07 (2022.01)] | 20 Claims |
|
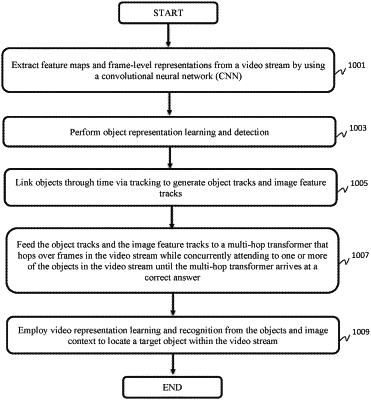
1. A method for using a multi-hop reasoning framework to perform multi-step compositional long-term reasoning, the method comprising:
extracting feature maps and frame-level representations from a video stream by using a convolutional neural network (CNN);
performing object representation learning and detection;
linking objects through time via tracking to generate object tracks and image feature tracks;
feeding the object tracks and the image feature tracks to a multi-hop transformer that hops over frames in the video stream while concurrently attending to one or more of the objects in the video stream until the multi-hop transformer arrives at a correct answer; and
employing video representation learning and recognition from the objects and image context to locate a target object within the video stream.
|