| CPC G06T 7/0004 (2013.01) [G06T 7/11 (2017.01); G06T 7/174 (2017.01); G06T 2207/20081 (2013.01); G06T 2207/20092 (2013.01); G06T 2207/30164 (2013.01)] | 20 Claims |
|
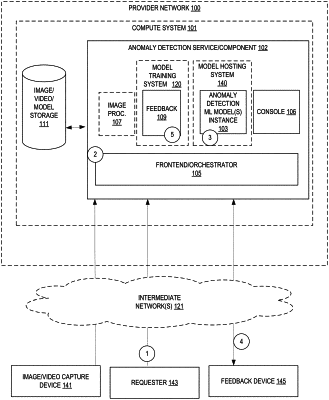
1. A computer-implemented method comprising:
receiving a request to create a training dataset from at least one image, the request including an indication of the at least one image and at least one indication of an operation to perform on the at least one image to generate a plurality of images from the at least one image;
creating the training dataset of images by extracting one or more chunks from a first image of the at least one image according to the request by performing one or more of:
extracting identically sized, non-overlapping chunks from the first image of the at least one image,
extracting non-identically sized chunks from the first image of the at least one image,
extracting any identified region of interest as a chunk from the first image of the at least one image, or
performing object detection on the first image of the at least one image and extracting any detected object of interest as a chunk; and
receiving one or more requests to train an anomaly detection machine learning model using the training dataset; and
training the anomaly detection machine learning model according to the one or more requests using the training dataset;
performing feedback-based training on the anomaly detection machine learning model by at least:
applying the anomaly detection machine learning model on a set of unlabeled testing data that is different than the training dataset to generate a prediction of whether the unlabeled testing data is anomalous,
receiving feedback on the prediction, wherein the feedback includes an indication of a veracity of the prediction,
generating an updated training dataset by updating the training dataset to include a label for correctly predicted data of the unlabeled testing data based on the feedback, and
retraining the anomaly detection machine learning model using the updated training dataset.
|