| CPC G06F 40/58 (2020.01) [G06F 40/284 (2020.01); G06F 40/295 (2020.01); G06F 40/49 (2020.01); G06N 3/08 (2013.01)] | 15 Claims |
|
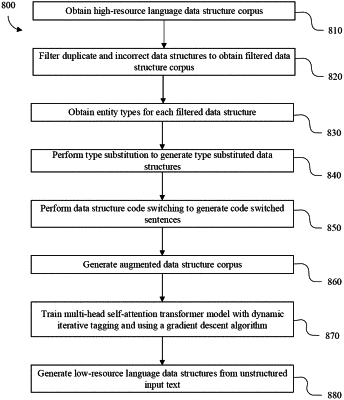
1. A method of extracting machine readable data structures from unstructured, low-resource language input text, the method comprising:
obtaining a corpus of high-resource language data structures,
filtering the corpus of high-resource language data structures to obtain a filtered corpus of high-resource language data structures,
obtaining entity types for each entity of each filtered high-resource language data structure,
performing type substitution for each obtained entity by replacing each entity with an entity of the same type to generate type substituted data structures,
replacing each entity with a corresponding low-resource language entity to generate code switched sentences,
generating an augmented data structure corpus comprising combining the type substituted data structures and code switched sentences with the filtered high-resource language data structure corpus,
training, using the augmented data structure corpus, a multi-head self-attention transformer model with dynamic iterative tagging and a gradient descent algorithm; and
providing the unstructured low-resource language input text to the trained multi-head self-attention transformer model to extract the machine readable data structures.
|