| CPC G06F 16/355 (2019.01) [G06F 16/313 (2019.01)] | 20 Claims |
|
1. A computer-implemented method, implemented in a computer system, comprising:
producing an item identifier corresponding to each unstructured data item of a plurality of unstructured data items, wherein
the producing comprises
performing a hashing operation on information associated with each of the plurality of unstructured data items;
storing each unstructured data item and its corresponding item identifier in association with one another in a storage device of the computer system;
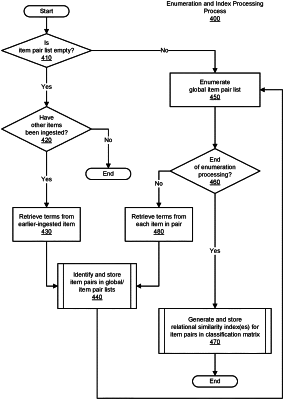
for each item of a plurality of items,
determining whether a backup operation should be performed on an item of the plurality of items, wherein
the item and each unstructured data item comprises unstructured data, and
the determining comprises
ingesting the item into a classification engine, wherein
the classification engine is implemented in the computer system, and
the ingesting comprises
generating an item identifier for the item, at least in part, by performing the hash operation on information associated with the item, and
storing the item identifier and item in association with one another in the storage device,
performing term processing, wherein
the performing the term processing comprises
determining a first number of occurrences of each term of a plurality of terms in the item, comprising
identifying at least one term of the plurality of terms in the item by determining a term frequency of each of the plurality of terms in the item, and
determining an inverse document frequency of the at least one term with respect to the plurality of unstructured data items, and
determining a second number of occurrences of each term of the plurality of terms in a reference item of unstructured data,
generating a similarity index, comprising
producing a first list of ranking values by ranking the plurality of terms in the item based on the first number of occurrences,
producing a second list of ranking values by ranking the plurality of terms in the reference item based on the second number of occurrences, and
determining a number of common ranking values, wherein
each ranking value is in the first list of ranking values and in the second list of ranking values, and
responsive to a size of the similarity index meeting a threshold,
determining a relational similarity index, wherein
the relational similarity index is based, at least in part, on a subset of the first list of ranking values and another subset of a list of ranking values for an unstructured data item of the plurality of unstructured data items, and
the relational similarity index represents a similarity between the item and the unstructured data item, and
in response to the relational similarity index indicating that the item and the unstructured data item are sufficiently similar, associating a classification tag with the item; and
performing a backup operation on one or more items of the plurality of items that are associated with the classification tag.
|