| CPC G06F 9/505 (2013.01) [G06F 9/44505 (2013.01); G06F 9/5044 (2013.01)] | 15 Claims |
|
1. A method of accelerating execution of one or more application tasks in a computing device using machine learning (ML) based model, the method comprising:
receiving an ML input task for execution on the computing device from a user;
retrieving a trained ML model and a corresponding optimal configuration file based on the received ML input task, wherein the optimal configuration file corresponding to each ML model includes a plurality of pre-defined configuration files obtained for one or more computing device functioning conditions;
obtaining a current performance status of the computing device for executing the ML input task; and
dynamically scheduling and dispatching parts of the ML input task to one or more processing units in the computing device for execution based on the obtained current performance status of the computing device,
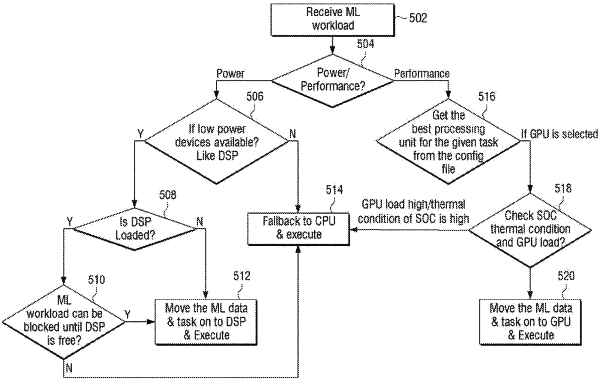
wherein the dynamically scheduling and dispatching comprises:
determining whether the ML input task is executed for low power or high performance,
if it is determined that the ML input task is to be executed for low power execution, checking availability of the low power processing unit,
if the low power processing unit is available to perform the ML input task, checking whether the low power processing unit is loaded,
if the low power processing unit is loaded with other input tasks, checking whether the ML input task can be blocked until the other input tasks are performed by the low power processing unit, and if the ML input task can be blocked, moving the parts of the ML input task to the low power processing unit for execution after the other input tasks are performed by the low power processing unit,
if the ML input task cannot be blocked or if the low power processing unit is not available to perform the ML input task, moving the parts of the ML input task to a first processing unit for execution,
if it is determined that the ML input task is to be executed for high performance execution, obtaining a second processing unit for the ML input task from the retrieved optimal configuration file, and checking the thermal condition of the computing device and load condition of the second processing unit,
if the thermal condition of the computing device is high or the load of the second processing unit is high, moving the parts of the ML input task to the first processing unit for execution, wherein the first processing unit has lower performance than the second processing unit, and
if the thermal condition of the computing device is low and the load of the second processing unit is low, moving the parts of the ML input task to the second processing unit for execution.
|