| CPC A63F 13/67 (2014.09) [A63F 13/44 (2014.09); A63F 13/822 (2014.09); G06N 3/08 (2013.01); A63F 2300/6009 (2013.01)] | 19 Claims |
|
1. A deep-learning based game play server configured to perform an action of arranging a manipulation puzzle in fixed puzzles arranged on a stage map and perform a match puzzle game in which when a predetermined number or more puzzles of a same color are arranged to be matched, the matched puzzles are removed and a score is provided, the deep-learning based game play server comprising:
at least one communicator configured to receive a plurality of first stage maps of a first size and a plurality of second stage maps of a second size;
a memory configured to store a deep-learning based agent model;
at least one processor configured to perform learning of the deep-learning based agent model by reading out the deep-learning based agent model and perform the match puzzle game using the learned deep-learning based agent model, the at least one processor configured to:
perform first reinforcement learning of the deep-learning based agent model to perform an action of obtaining the score on the plurality of second stage maps,
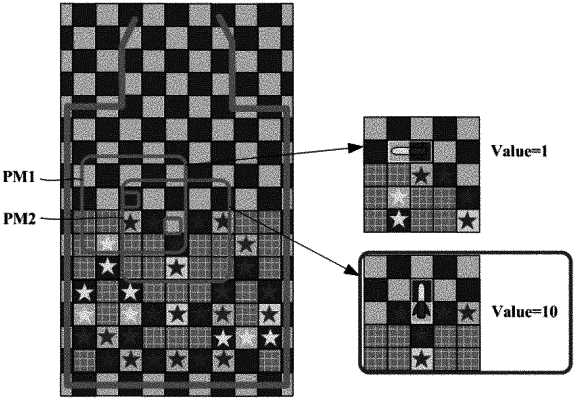
generate a plurality of partition stage maps, wherein each of the plurality of partition stage maps is a part of the plurality of first stage maps with the second size, and includes one or more of the fixed puzzles,
generate a training data set with each of the plurality of first stage maps as an input data and an action of obtaining a highest score among actions on the plurality of partition stage maps as a correct answer label,
perform teacher learning of the deep-learning based agent model, performed of the first reinforcement learning, by using the training data set, and
perform second reinforcement learning of the deep-learning based agent model,
performed of the teacher-learning, for the plurality of the first stage maps.
|