| CPC H04N 21/8106 (2013.01) [H04N 21/4394 (2013.01); H04N 21/44008 (2013.01); H04N 21/4884 (2013.01); H04N 21/8456 (2013.01)] | 20 Claims |
|
1. A computer-implemented method for creating a scripting data for dubbed audio of a media data, the method comprising:
receiving, by one or more processors, the media data comprising one or more recorded vocal instances;
extracting, by the one or more processors, the one or more recorded vocal instances from an audio portion of the media data;
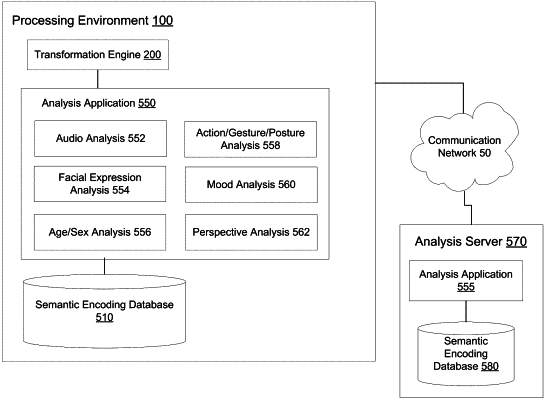
determining, by the one or more processors, a semantic encoding for a human-perceivable message encoded in the media data based on an analysis of a scene or a character represented in the one or more recorded vocal instances;
assigning, by the one or more processors, a time code to each of the extracted vocal instances and to the determined semantic encoding, correlated to a specific frame of the media data;
converting, by the one or more processors, the extracted recorded vocal instances into a text data;
generating, by the one or more processors, a dubbing list comprising the text data and the time code;
displaying, by the one or more processors, a selected portion of the dubbing list corresponding to the one or more vocal instances;
assigning, by the one or more processors, a set of annotations corresponding to the one or more vocal instances based on the determined semantic encoding; and
generating, by the one or more processors, the scripting data comprising the dubbing list and the set of annotations.
|