| CPC G10L 15/22 (2013.01) [G06F 3/167 (2013.01); G06F 40/134 (2020.01); G06F 40/169 (2020.01); G06F 40/279 (2020.01); G06Q 10/087 (2013.01); G06Q 30/0635 (2013.01); G06F 16/951 (2019.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
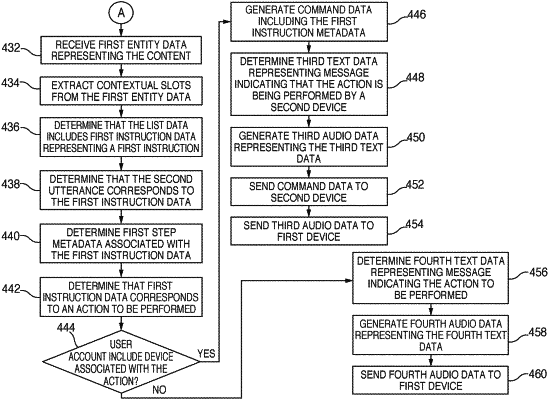
1. A computer-implemented method, comprising:
receiving first input audio data representing an utterance;
performing speech processing on the first input audio data to determine a first request to output data corresponding to a plurality of steps of a first process, the plurality of steps including at least a first step, a second step, and a third step;
causing a first device to present first output data corresponding to the first step;
receiving input data corresponding to a second process corresponding to the second step;
determining second output data corresponding to the second process; and
after receiving the input data corresponding to the second process, causing the first device to present third output data corresponding to the third step.
|