| CPC G06V 30/41 (2022.01) [G06V 30/19013 (2022.01); G06V 30/19173 (2022.01)] | 29 Claims |
|
1. A computer implemented method for training a machine learning model for detecting fraud in a document of a class of documents, the method comprising:
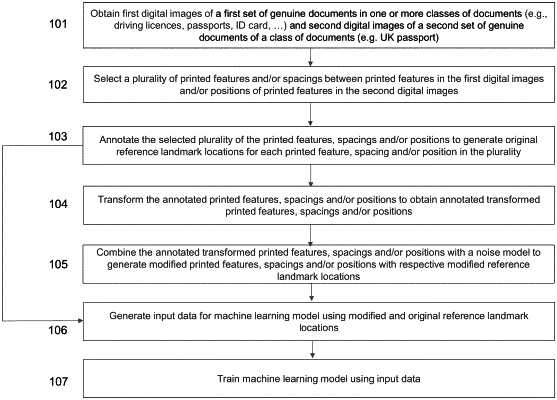
(i) obtaining first digital images of a first set of genuine documents in one or more classes of documents and second digital images of a second set of genuine documents of the class of documents, each second digital image being an image of a region of the respective document comprising a portion of or the whole respective document, wherein the second set of genuine documents are the same as, different from, or a subset of the first set of genuine documents;
(ii) selecting at least one of a plurality of printed features and a plurality of spacings between the plurality of printed features in the first digital images of the first set of genuine documents and a plurality of positions of a plurality of printed features in the second digital images;
(iii) annotating the selected at least one of the plurality of printed features, the plurality of spacings between the plurality of printed features and the plurality of positions of the plurality of printed features to obtain a plurality of original reference landmark locations for each printed feature, spacing and position in the at least one of the plurality of printed features, spacings and positions;
(iv) transforming the annotated at least one of the plurality of printed features, the plurality of spacings between the plurality of printed features and the plurality of positions of the plurality of printed features against a plurality of other instances of the respective annotated printed feature, annotated spacing and/or annotated position to obtain at least one of a plurality of annotated transformed printed features, a plurality of annotated transformed spacings and/or a plurality of annotated transformed positions;
(v) combining the at least one of the plurality of annotated transformed printed features, the plurality of annotated transformed spacings and the plurality of annotated transformed positions with a noise model to generate at least one of a plurality of modified printed features, a plurality of modified spacings and a plurality of modified positions for each respective printed feature, spacing and position in the first digital images, wherein each modified printed feature, modified spacing and modified position comprises a plurality of annotations that indicate a plurality of modified reference landmark locations for the respective modified printed feature, modified spacing and modified position;
(vi) generating input data for the machine learning model using the plurality of original reference landmark locations and the plurality of modified reference landmark locations;
(vii) training the machine learning model using the input data.
|