| CPC G06T 7/215 (2017.01) [G06F 18/214 (2023.01); G06N 3/045 (2023.01); G06N 3/049 (2013.01); G06N 3/084 (2013.01); G06T 2207/10016 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01)] | 17 Claims |
|
1. A computer-implemented neural network system for processing input video data representing input video image frames to decompose the input video data into two or more sets of decomposed video data each representing a respective sequence of decomposed video image frames, the sequences of decomposed video image frames representing a decomposition of the input video image frames, the neural network system comprising:
a video data input to receive a sequence of input video image frames;
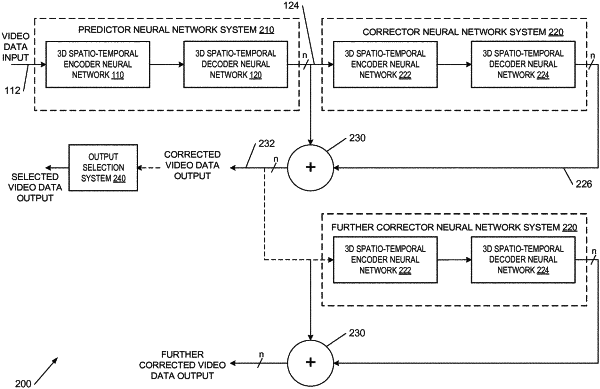
a predictor 3D spatio-temporal encoder neural network to encode the sequence of input video image frames into a first set of latent variables representing a compressed version of the input video image frames;
a predictor 3D spatio-temporal decoder neural network to receive and process the first set of latent variables to generate two or more sets of decomposed video data representing respective sequences of decomposed video image frames;
a video data output to output video data derived from one or more of the sets of decomposed video data;
a corrector 3D spatio-temporal encoder neural network to receive each of the sets of decomposed video data and to encode the respective sequences of decomposed video image frames into a second set of latent variables representing a compressed version of the sequences of decomposed video image frames;
a corrector 3D spatio-temporal decoder neural network to receive and process the second set of latent variables to generate two or more sets of correction video data, a set of correction video data for each set of decomposed video data; and
a combiner to combine each set of decomposed video data with a respective set of correction video data to provide two or more sets of combined video data, wherein the video output data comprises one or more of the sets of combined video data.
|