| CPC G06N 3/092 (2023.01) [G06N 3/042 (2023.01); G06N 3/047 (2023.01); G06N 3/08 (2013.01); G06N 5/025 (2013.01); G06N 3/006 (2013.01); G06N 7/01 (2023.01); G06N 20/00 (2019.01)] | 20 Claims |
|
10. A computing system, comprising:
a memory comprising executable instructions; and
a processor configured to execute the instructions to cause the computing system to at least:
compute a reward value based at least in part on a similarity between a plurality of model predictions from a pre-trained model and a plurality of agent predictions from a Reinforcement Learning (RL) agent;
perform each step of one or more steps of a rule of a plurality of rules, wherein the rule is assigned a weight and wherein the rule comprises a protected attribute, a cumulative statistic value type, and a comparison threshold, the one or more steps being:
extract a set of biased agent predictions from the plurality of agent predictions corresponding to each biased record of a set of biased records, the set of biased records generated from a plurality of records of an input dataset fed to the RL agent, wherein for a biased record of the set of biased records, an attribute value of the protected attribute is within a pre-determined set of biased values of the protected attribute;
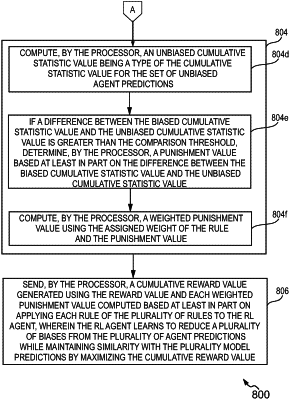
compute a biased cumulative statistic value being a type of the cumulative statistic value for the set of biased agent predictions;
extract a set of unbiased agent predictions from the plurality of agent predictions corresponding to each unbiased record of a set of unbiased records, the set of unbiased records generated from the plurality of records of the input dataset fed to the RL agent, wherein for an unbiased record of the set of unbiased records, the attribute value of the protected attribute is within a pre-determined set of unbiased values of the protected attribute;
compute an unbiased cumulative statistic value being a type of the cumulative statistic value for the set of unbiased agent predictions;
if a difference between the biased cumulative statistic value and the unbiased cumulative statistic value is greater than the comparison threshold, determine a punishment value based at least in part on the difference between the biased cumulative statistic value and the unbiased cumulative statistic value; and
compute a weighted punishment value using the assigned weight of the rule and the punishment value; and
send a cumulative reward value generated using the reward value and each weighted punishment value computed based at least in part on applying each rule of the plurality of rules to the RL agent, wherein the RL agent learns to reduce a plurality of biases from the plurality of agent predictions while maintaining similarity with the plurality of model predictions by maximizing the cumulative reward value.
|