| CPC G06N 3/08 (2013.01) [G06F 18/214 (2023.01); H04L 63/205 (2013.01)] | 20 Claims |
|
1. A method of training a policy neural network having a plurality of policy parameters and used to select actions to be performed by an agent to control the agent to perform a particular task while interacting with one or more other agents in an environment, the method comprising:
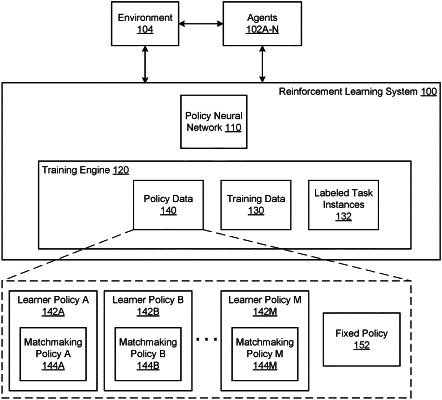
maintaining data specifying a pool of candidate action selection policies, the pool of candidate action selection policies comprising:
(i) a plurality of learner polices for controlling the agent, wherein each learner policy is defined by a respective set of adjustable policy parameters of the policy neural network that are adjusted during the training of the policy neural network, and
(ii) one or more fixed policies for controlling the agent, wherein each fixed policy is defined by a respective set of nonadjustable policy parameters that are not adjusted alongside the respective sets of adjustable policy parameters during the training of the policy neural network, and wherein during the training, at least some of actions performed by the one or more other agents are selected by using the one or more fixed policies and in accordance with the respective sets of nonadjustable policy parameters;
maintaining, for each of the learner policies, data specifying a respective matchmaking policy for the learner policy that defines a distribution over the pool of candidate action selection policies;
at each of a plurality of training iterations:
for each of one or more of the learner policies:
selecting one or more policies from the pool of candidate action selection policies using the matchmaking policy for the learner policy;
generating training data for the learner policy by causing a first agent controlled using the learner policy to perform the particular task while interacting with one or more second agents, each second agent controlled by a respective one of the selected policies; and
updating the respective set of policy parameters that define the learner policy by training the learner policy on the training data through reinforcement learning to optimize a reinforcement learning loss function for the learner policy.
|