| CPC G06N 3/045 (2023.01) [G06N 3/08 (2013.01)] | 18 Claims |
|
1. A system comprising:
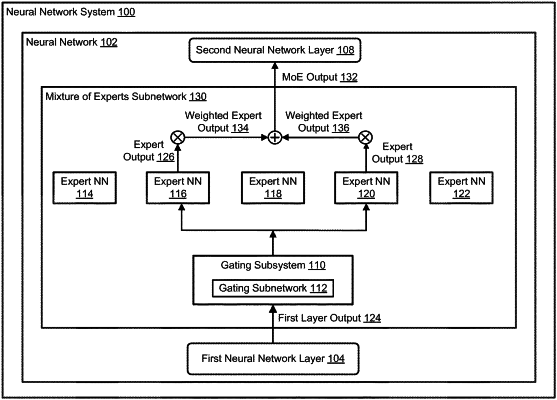
a main neural network implemented by one or more computers, the main neural network comprising a Mixture of Experts (MoE) subnetwork that comprises:
a plurality of expert neural networks, wherein the main neural network is configured to receive an input text sequence as input and to process the input text sequence to generate a network output, wherein the input text sequence has respective text located at a plurality of corresponding positions, and
a gating subsystem configured to:
for each position in the input text sequence, select a respective combination of one or more expert neural networks from the plurality of expert neural networks to be active for the processing of the text located at the position by the main neural network, wherein the gating subsystem is configured to select the respective combination of the one or more expert neural networks based on at least one of a syntax or semantics of the text located at the position.
|