| CPC G06F 40/284 (2020.01) [G06F 40/242 (2020.01); G06N 20/00 (2019.01); G06V 30/268 (2022.01); G06V 30/414 (2022.01); H04L 9/3236 (2013.01)] | 15 Claims |
|
1. A method, performed by a computer system, for text sanitization, the method comprising:
building a corpus of document vectors by performing the following:
obtaining a plurality of documents;
tokenizing each of the plurality of documents;
for each of the plurality of documents, creating a vector representation of the document based on the tokens in the document;
building a corpus of document vectors comprising the vector representations for the plurality of documents;
obtaining a new document for text sanitization;
tokenizing the new document;
creating a new document vector based on the tokens in the new document;
accessing the corpus of document vectors;
filtering each of the tokens in the new document against a privacy threshold, wherein any tokens having a frequency in the corpus of document vectors below the privacy threshold are flagged as unsafe;
performing a k-anonymity sanitization process such that the new document vector becomes indistinguishable from at least k other document vectors in the corpus of document vectors, wherein k is a positive integer, and wherein, during the k-anonymity sanitization process, tokens in the document are flagged as either safe or unsafe;
replacing or redacting the tokens in the document flagged as unsafe, wherein replacing or redacting the tokens in the document flagged as unsafe comprises the following for each token flagged as unsafe;
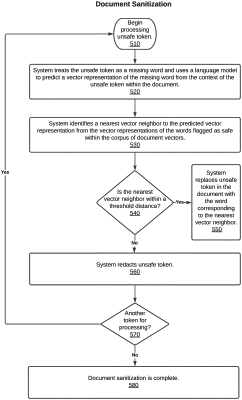
treating the unsafe token as a missing word and using a machine-learning language model to predict a vector representation of the missing word from a context of the unsafe token within the document,
obtaining a predicted vector representation for the missing word from the machine-learning language model,
identifying a nearest vector neighbor to the predicted vector representation from the vector representations of words flagged as safe within the corpus of document vectors,
determining whether the nearest vector neighbor is within a threshold distance of the predicted vector representation,
in response to the nearest vector neighbor being within a threshold distance of the predicted vector representation, replacing the unsafe token in the document with the word corresponding to the nearest vector neighbor, and
in response to the nearest vector neighbor not being within a threshold distance of the predicted vector representation, redacting the unsafe token from the document; and
updating the corpus of document vectors to include the new document vector in its form prior to the filtering and k-anonymity sanitization steps.
|