| CPC G06F 16/3328 (2019.01) [G06F 16/358 (2019.01); G06V 30/412 (2022.01)] | 20 Claims |
|
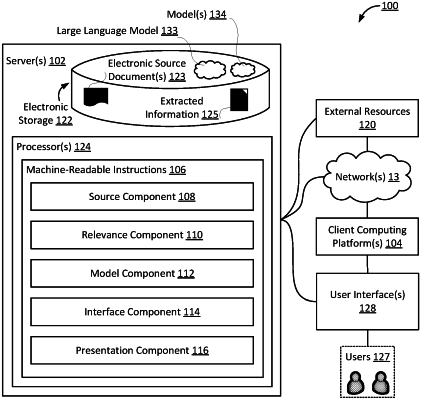
1. A system configured for providing user interfaces for configuration of a flow for extracting information from documents via a large language model, wherein the large language model has been trained on at least a million documents, wherein the large language model includes a neural network using over a billion parameters and/or weights, the system comprising:
one or more hardware processors configured by machine-readable instructions to:
effectuate a presentation of a user interface, the user interface being configured to obtain entry of user input from a user to:
(i) select a set of exemplary documents to be provided as input to configure the flow for extracting information from a corpus of electronic documents,
(ii) select and/or modify one or more document classifications from a set of document classifications for the set of exemplary documents,
(iii) select and/or modify one or more extraction fields from a set of extraction fields for an individual document classification from the set of document classifications, and
(iv) navigate between a set of different portions of the user interface, wherein the set of different portions includes:
(a) a first portion configured to select, by the user, an individual flow from a set of flows for information extraction,
(b) a second portion configured to select and/or modify, by the user, individual document classifications from the set of document classifications, wherein individual documents from the set of exemplary documents are classified into individual ones of the set of document classifications,
(c) a third portion configured to select and/or modify, by the user, a particular document classification for a particular individual document, wherein the particular individual document has been classified into the particular document classification, and
(d) the fourth portion configured to select and/or modify the set of extraction fields for the particular document classification, wherein individual extraction fields correspond to individual queries that are provided as prompts to the large language model, using the particular individual document as context;
responsive to selection of the individual flow, present the set of document classifications in the second portion;
subsequent to selection of the particular document classification in the second portion, present the particular individual document in the third portion; and
subsequent to the selection of the particular document classification in the second portion, present the set of extraction fields in the fourth portion, wherein the individual extraction fields present individual replies obtained from the large language model in reply to the individual queries.
|