| CPC G06F 16/254 (2019.01) [G06F 16/116 (2019.01)] | 16 Claims |
|
1. A system for supporting the use of key flex field in analytics application environment, comprising:
a computer including a processor;
a source dataset associated with a tenant, the source dataset comprising key flex fields of the first tenant comprising a plurality of segments associated with the tenant;
a second source dataset associated with a second tenant, the second source data comprising key flex fields of the second tenant comprising a plurality of segments associated with the second tenant; and
a data warehouse, the data warehouse comprising a first storage schema shareable by multiple tenants, a second storage schema being associated with the tenant, and a third storage schema being associated with the second tenant;
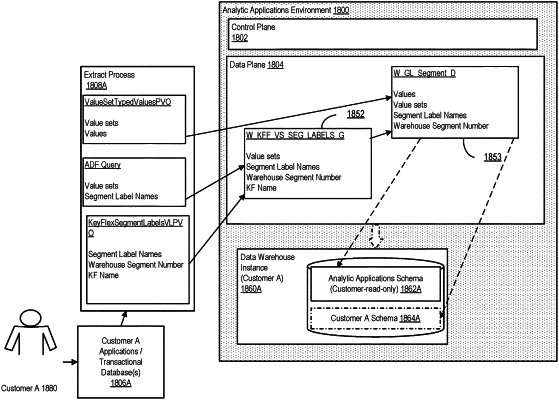
wherein segment label names, and corresponding value sets and data values are extracted from the key flex fields of the first tenant and the key flex fields of the second tenant by the processor;
wherein the segment label names, and corresponding value sets, and data values extracted from the key flex fields of the first tenant are joined to form a first joined table by the processor, the first joined table comprising a mapping data and tenant data of the first tenant, wherein the segment label names, and corresponding value sets, and data values extracted from the key flex fields of the second tenant are joined to form a second joined table by the processor, the second joined table comprising the mapping data and tenant data of the second tenant, wherein the mapping data is based at least in part on a context of the key flex fields corresponding to each of the multiple tenants;
wherein the mapping data is loaded at the first storage schema by the processor;
wherein the first joined table is loaded at the second storage second schema associated with the first by the processor;
wherein the second joined table is loaded at the third storage schema associated with the second tenant by the processor;
wherein reports associated with the first tenant and the source dataset are dynamically created based on the mapping data stored at the first storage schema by the processor; and
wherein reports associated with the second tenant and the second source dataset are dynamically created based on the mapping data stored at the first storage schema by the processor.
|