| CPC G10L 25/63 (2013.01) [G06V 40/176 (2022.01); B60W 2040/089 (2013.01)] | 18 Claims |
|
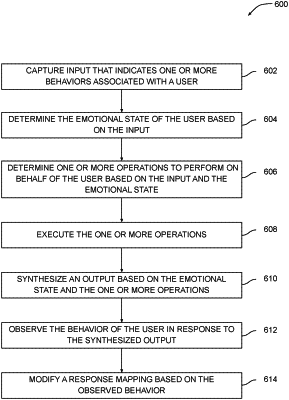
1. A computer-implemented method for causing a virtual personal assistant to interact with a user while assisting the user, the method comprising:
capturing, by an input device of the virtual personal assistant, a first input that indicates one or more behaviors associated with the user;
determining, by a processor of the virtual personal assistant, a first emotional state of the user based on the first input;
selecting, by the processor using a machine learning model stored in a memory of the virtual personal assistant, a first emotional component for changing the first emotional state of the user to a first target emotional state of the user, wherein the machine learning model maps the first target emotional state of the user to the first emotional component for changing the first emotional state of the user to the first target emotional state of the user, and the machine learning model maps a second target emotional state of the user to a second emotional component for changing a second emotional state of the user to the second target emotional state of the user, wherein the first target emotional state of the user is different from the second target emotional state of the user, wherein the first emotional component comprises at least one of a pitch of speech, a laugh, a cough, a whistle, one or more non-speech alert sounds, a stress frequency of speech, a contour slope of speech, a final lowering of speech, a breathiness quality of speech, a laryngealization of speech, a pause discontinuity of speech, or a pitch continuity of speech;
generating, by the processor, a first vocalization that incorporates the first emotional component, wherein the first vocalization relates to a first operation that is being performed by the virtual personal assistant to assist the user;
outputting, by an audio output device of the virtual personal assistant, the first vocalization to the user;
capturing, by the input device of the virtual personal assistant, a second input that indicates at least one behavior the user performs in response to the outputting of the first vocalization;
determining, by the processor, an updated emotional state of the user based on the second input; and
modifying, by the processor, the machine learning model based on the updated emotional state of the user and the first target emotional state of the user.
|