| CPC G10L 17/18 (2013.01) [G06N 3/045 (2023.01); G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/16 (2013.01); G10L 17/04 (2013.01)] | 21 Claims |
|
1. A system comprising:
a processing unit; and
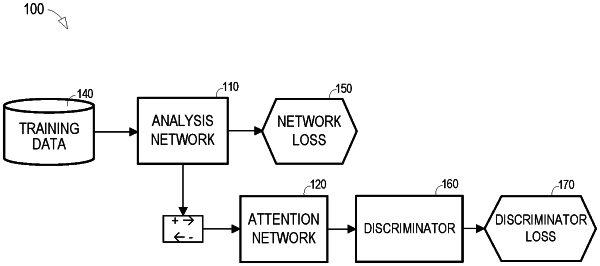
a memory storage device including program code that when executed by the processing unit causes the system to use an acoustic model trained for automatic speech recognition to:
receive speech frames and extract features from the speech frames based on a first set of parameters of the acoustic model for feature extraction;
identify senone probabilities based on the extracted features and on a second set of parameters of the acoustic model for senone classification; and
identify words represented by the speech frames based on the senone probabilities,
wherein the first set of parameters and the second set of parameters have been modified during training of the acoustic model to minimize a senone classification loss associated with the second set of parameters,
wherein the first set of parameters has been modified during training of the acoustic model to maximize the domain classification loss associated with the first set of parameters,
wherein a third set of parameters of the acoustic model for applying attention weights and a fourth set of parameters of the acoustic model for domain classification have been modified during training of the acoustic model to minimize the domain classification loss associated with the fourth set of parameters, such that (i) the third set of parameters is used during training of the acoustic model to determine relative importance related to domain classification of the extracted features and the fourth set of features is used during training of the acoustic model to classify a domain of an extracted feature.
|