| CPC G10L 15/20 (2013.01) [G10L 15/02 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01); G10L 15/063 (2013.01); G10L 21/0208 (2013.01)] | 19 Claims |
|
1. A method implemented by one or more processors, the method comprising:
invoking an automated assistant client at a client device, wherein invoking the automated assistant client is in response to detecting one or more invocation queues in received user interface input;
in response to invoking the automated assistant client:
processing initial spoken input received via one or more microphones of the client device;
generating a responsive action based on the processing of the initial spoken input;
causing performance of the responsive action;
automatically monitoring for additional spoken input after causing performance of at least part of the responsive action;
receiving audio data during the automatically monitoring;
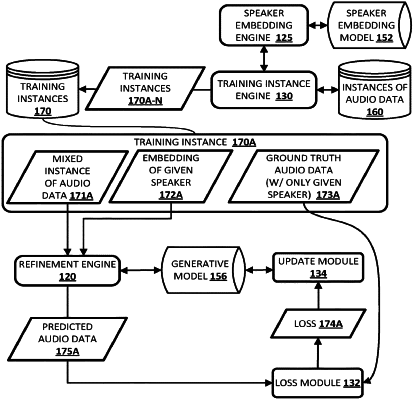
generating a refined version of the audio data, wherein the refined version isolates any of the audio data that is from the human speaker, wherein generating the refined version of the audio data comprises:
identifying a speaker embedding for the human speaker that provided the initial spoken input; and
processing the audio data using and the speaker embedding using a trained generative model; and
determining, based on the refined version of the audio data, whether the audio data includes an additional spoken input that is from the same human speaker that provided the initial spoken utterance; and
in response to determining that the audio data does include additional spoken input that is from the same human speaker:
performing certain further processing that is based on the additional spoken input.
|